




テキストファイルと内容のポータビリティ
テキストファイルに落とせば、MacintoshでもWindowsでも、UNIXでも利用できるじゃないか、という人もいるでしょう。確かにその通り。テキストファイルはもっとも互換性の高いデータです。ある意味では。
同じプラットフォームという枠内でも、同じアプリケーションを持っていない人同士が電子書類をやり取りするときは、テキスト形式で保存して渡すのが一番手っ取り早い方法に違いありません。MacintoshからWindowsへというように別のプラットフォームへ持っていくときも、フロッピーディスクなどの物理メディアの互換性の問題を克服する方法はいろいろあるので、テキストファイルなら何とかなります。MacintoshベースのDTPでレイアウトする場合でも、電算写植で処理する場合でも、執筆者からテキストファイルをもらえば再度入力する手間が省けます。その人が使っているパソコンとワープロソフトが何であろうと関係なし。たとえワープロ専用機だったとしてもDOSフォーマットのフロッピーディスクにテキスト形式で保存できる機種であれば大丈夫。というわけで、出版物の原稿を入稿する現場では、テキストのみのファイルで渡すというのが無難なやり方として受け入れられています。パソコン通信やインターネットがこれだけ普及した現在、テキスト形式のファイルを電子メールで入稿するというケースも多くなっているようです。
インターネットの電子メールは、クロスプラットフォームで実用的にテキストファイルのやり取りが行われている場所だと考えることができます。相手が MacintoshだろうがWindowsだろうが、はたまたUNIXであっても、そんなことは気にしないでメールを送信していますよね。それでも問題なく相手が読める状態で届きます。ほとんどの場合は。実際は、文字化けして読めまっせ〜ん、ということが時々あるのも事実です。これは、なぜでしょう?
コンピュータがテキストを扱うためには、それぞれの文字にコードが割り当てられていなければなりません。これが「符合化」といわれるもので、日本語の符号化方式で代表的なのがJISコードとシフトJISコード、そしてEUC(拡張UNIXコード)です。大まかにいえば、パソコン系が採用しているのがシフト JIS、UNIX系はEUCです。JISコードはコンピュータの内部処理にはほとんど使われていませんが、コンピュータ間で情報の交換を行う際(たとえば、インターネット上の電子メールの送受信)の符号化方式としては最も一般的です。異なる符号化方式の間では、変換を行わないとテキストをやり取りできません。たとえば、パソコンのユーザがワークステーション(UNIX)のユーザ宛に電子メールを送ったとすると、3種類の異なった符号化方式の間での変換処理が発生します。まず、パソコン側ではシフトJISコードで処理されているメールのテキストをJISコードに変換します。それをインターネット上に送り出します(つまりインターネット上はJISコードでテキストが流れるわけです)。JISコードでデータを受け取ったワークステーション側は、JISコードからEUCへの変換を行います。これで、やっとメールのテキストとして読めるようになります。この一連のプロセスのどこかで変換に失敗すれば、訳のわからない文字化け状態になってしまうわけです。
JISとシフトJIS、EUC以外のマイナーな方式の存在を抜きにすれば、符号化方式の違いと変換処理そのものは大きな問題とはいえません。実は、符号化の対象となっている「文字セット」の方に大きな問題が潜んでいるのです。簡単な例をあげてこの問題を説明してみましょう。
Windowsのワープロソフト(Wordとか一太郎とか)で原稿を作成し、それをテキストファイルに落として、 Macintoshで誌面を作っているデザイナーに渡したとします。Macintosh上でデザイナーが開いたテキストファイルを見てみると、原稿の中に入っている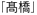 *1 さんの名前が黒いお豆腐のような「■橋」になっている!
*1 さんの名前が黒いお豆腐のような「■橋」になっている!
Windows上ではちゃんと表示されていた*1 さんの名前が「■橋」になってしまったのは、*1 さんの名前を新字体の「高」ではなく、異体字で正しく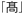 *2 と入力していたからです。この文字のコードはFBFCで、WindowsとMacintoshが採用している符号化方式であるシフトJISでは「ユーザ定義領域」と呼ばれているエリアに含まれています。このユーザ定義領域は、メーカーが独自に文字を割り当てて拡張している部分です。このため、同じ符号化方式であってもメーカーごとに違いが生じています。Macintoshではちょうどそこに文字が割り当てられていないので、黒いお豆腐状態になって表示されたわけです(逆に、Macintoshの方で別の異体字か旧字体がそこに割り当てられていたとしたら、
*2 と入力していたからです。この文字のコードはFBFCで、WindowsとMacintoshが採用している符号化方式であるシフトJISでは「ユーザ定義領域」と呼ばれているエリアに含まれています。このユーザ定義領域は、メーカーが独自に文字を割り当てて拡張している部分です。このため、同じ符号化方式であってもメーカーごとに違いが生じています。Macintoshではちょうどそこに文字が割り当てられていないので、黒いお豆腐状態になって表示されたわけです(逆に、Macintoshの方で別の異体字か旧字体がそこに割り当てられていたとしたら、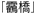 *3 なんて表示されて、別人の名前になってしまう可能性もあるわけです)。つまりこれは、WindowsとMacintoshの間では「文字セットに互換性がない」ということを意味しています。
*3 なんて表示されて、別人の名前になってしまう可能性もあるわけです)。つまりこれは、WindowsとMacintoshの間では「文字セットに互換性がない」ということを意味しています。
文字セットとは、ある目的のために選択した文字の集合体です。たとえば「常用漢字」は、教科書などで使うための文字を集めた文字セットということになります。常用漢字がコンピュータでの利用を念頭に入れていないのに対して、電子的な利用のために政府が規定したものに「情報交換用漢字符号」と呼ばれる文字セット規格があります。よく耳にするJIS第一・第二水準の漢字というのも、これの一部(つまり漢字の部分)です。この文字セット規格には制定年度ごとの名前が付いたいくつかの版(JIS X 0208-1990とか)があり、それぞれの版で文字数や字形の違いがあります。また、約6,000文字を新たに定義した拡張文字セット規格(JIS X 0212-1900)などというのまであり、かなり複雑な状態になっています。どのコンピュータメーカーもこの文字セット規格(のいずれかの版)に準拠していますが、それぞれが独自に外字を加えたりして文字セットを拡張しているために、余計にややこしくなっています。パソコンだけでなく、電子メディア全体という大きな範囲を見渡せば、IBM漢字だとかNEC漢字、Apple90、FMR漢字、NTT漢字……など、それぞれ互換性のない文字セットが存在していて超カオス状態になっていることがわかります。さらに、同一のプラットフォームであっても、文字セットが完全に統一されてはいない場合もあります。たとえば、漢字Talk 7.1のリリースに際してアップル社がそれまでの文字セットに若干の変更を加えてしまっため、記号類に関してDTP業界で混乱が生じたことがあります。これは、それまで文字が定義されていなかった部分にアップルが新たに文字を追加したため、新しいフォントと従来のフォントの間で互換性がなくなったという問題でした。
このように、テキストのみのファイルをやり取りする場合でも、問題なく情報を交換できるとは限りません。まあ、*1 さんには「高橋」という表記で我慢してもらい、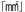 *4 などの記号は一切使わずに「mm2」とか「平方ミリメートル」と書くようにすれば実用上は問題ないでしょう。とりあえず内容はきちんと伝わります。言い換えれば、テキストファイルで情報を伝達するとき“内容のポータビリティ”はかなり満足されるということです。しかし、テキストファイルで情報を交換しているかぎり、当然ながらフォントや書式などのレイアウトの要素、そして画像を含むビジュアルデザイン的な要素はすべて失われ、純粋に文章(テキスト)のみが素っ裸でやり取りされるだけになります。
*4 などの記号は一切使わずに「mm2」とか「平方ミリメートル」と書くようにすれば実用上は問題ないでしょう。とりあえず内容はきちんと伝わります。言い換えれば、テキストファイルで情報を伝達するとき“内容のポータビリティ”はかなり満足されるということです。しかし、テキストファイルで情報を交換しているかぎり、当然ながらフォントや書式などのレイアウトの要素、そして画像を含むビジュアルデザイン的な要素はすべて失われ、純粋に文章(テキスト)のみが素っ裸でやり取りされるだけになります。
ここで忘れてはならないのが、情報には“表現”という重要な要素があるということです。確かに情報を伝達するために我々が使う最も有効な表現手段が言葉であり、電子メディアにおいてもテキスト(文章)のみという形でなら“内容のポータビリティ”を保ったまま情報のやり取りが可能です。しかし、それに写真やイラストなどの表現手段が加わり、デザインやレイアウトというさらに別の表現手段でひとつにまとめられたとき、情報はより完全なものとなるはずです。どれほど純粋な活字至上主義者のライターや編集者であっても「ビジュアル的な要素は断固排除すべし」とか「文字の大きさや書体を変えて見出しを強調するのは姑息な手段だ」とか「すべて同じ書体の同じポイントサイズで書かれていてこそ由緒正しい文章である」というような極端な主張をする人はあまりいないでしょう。電子メディアによる情報伝達においても、文章以外の表現手段を無視してしまうわけにはいきません。したがって電子メディアにおける情報伝達を考えるときには、内容のポータビリティだけではなく“表現のポータビリティ”も考慮しなければならないでしょう。
*1 (たかはし)
(たかはし)
*2 (たか)
(たか)
*3
*4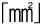 (平方ミリメートル)
(平方ミリメートル)